
- October 2 - 6, 2023
- PARIS, FR
ICCV 2023
2023 International Conference on Computer Vision (ICCV)
ICCV is the premier international computer vision event comprising the main conference and several co-located workshops and tutorials.
We look forward to this year's exciting sponsorship and exhibition opportunities, featuring a variety of ways to connect with participants in person. Sony will exhibit and participate as a Silver sponsor.
Recruiting information for ICCV-2023
We look forward to working with highly motivated individuals to fill the world with emotion and to pioneer future innovation through dreams and curiosity. With us, you will be welcomed onto diverse, innovative, and creative teams set out to inspire the world.
At this time, the full-time and internship roles previously listed on this page are closed.
As such, please see all our other open positions through the links below.
Sony AI: https://ai.sony/joinus/jobroles/
Global Careers Page: https://www.sony.com/en/SonyInfo/Careers/japan/
NOTE: For those interested in Japan-based full-time and internship opportunities, please note the following points and benefits:
・Japanese language skills are NOT required, as your work will be conducted in English.
・Regarding Japan-based internships, please note that they are paid, and that we additionally cover round trip flights, visa expenses, commuting expenses, and accommodation expenses as part of our support package.
・Regarding Japan-based full-time roles, in addition to your compensation and benefits package, we cover your flight to Japan, shipment of your belongings to Japan, visa expenses, commuting expenses, and more!
Technologies & Business use case
Technology 01Technologies & Business use case
Federated Learning and Vision Foundation Model Development
Traditional machine learning training methods require centralizing a large amount of
data from diverse sources to a
single server. However, the growing concern over data privacy, particularly for
applications that involve sensitive
personal information, is making this training paradigm a huge concern. Federated
learning (FL) revolutionizes the
traditional centralized training paradigm by enabling model training from decentralized
data without any data sharing
with the central server.
Meet Sony AI Privacy and Security Team to know more about how we developed extensive
experience in FL research and
extend it to computer vision application and vision foundation model development. We
have published numerous papers in
top-tier AI conferences and journals (e.g., NeurIPS, ICLR, ICML, Nature Communications,
etc.).
Selected related publications:
-
・When Foundation Model Meets Federated Learning: Motivations, Challenges, and Future Directions
-
・[ICCV'23] TARGET: Federated Class-Continual Learning via Exemplar-Free Distillation
-
・[ICCV'23] MAS: Towards Resource-Efficient Federated Multiple-Task Learning
-
・[ICLR'23] MocoSFL: enabling cross-client collaborative self-supervised learning
We are actively recruiting (senior) research scientists and research engineers with expertise in vision foundation models and computer vision applications to join us. Please send your resume to lingjuan.lv@sony.com or weiming.zhuang@sony.com, if you are interested.
You can apply for an internship with us via https://ai.sony/joinus/job-roles/research-intern-privacy-preserving-machine-learning/.
Technology 02Deep Generative Models for Music and Content Creators
At Sony Research, we believe that deep learning models will power the majority of the tools and software used
by audio
professionals in the future. The advancements of AI in this direction will help creators achieve goals that
would be
unfeasible with today’s technology, pushing the boundaries of creation in a radical way.
Understanding how audio and media professionals can benefit from the new possibilities offered by AI is at the
core of
our mission and our work is driven by our willingness to solve real-world problems. Our research spans a wide
range of
topics, from developing foundational deep learning techniques to more application-oriented works. By working
closely
with content creators and with world-leading entertainment groups, we aim at creating human-centric technology
allowing
them to fulfill their wildest artistic dreams.
Meet Sony AI Music Foundation Model team to see how we build up the next generation of AI tools in collaboration
with
artists and professionals.
A list of our publications is available at https://sony.github.io/creativeai/.
Technology 03Image Recognition Technologies in Sony R&D
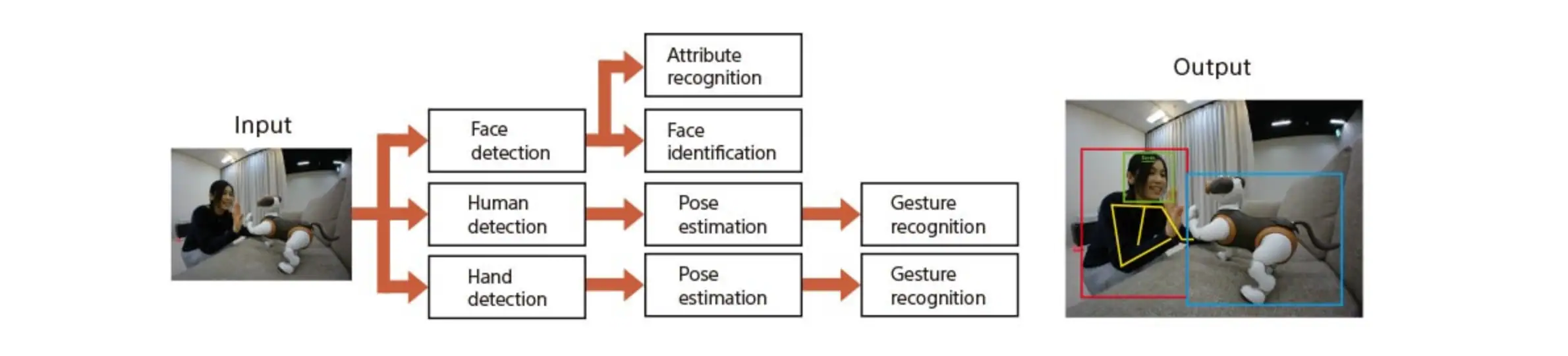
Image recognition technology is one of the most successful AI technologies commercialized in Sony products. We have been developing image recognition technologies for more than 20 years. Started from AIBO in 1999, we have developed many functions such as face recognition, human recognition, and object recognition. Our AI model is lightweight and able to run on edge devices in real time. The talk includes a brief history of our image recognition technologies associated with products and services at that time, and current research and development items.
Technology 04Deep Generative Modeling
Technologies like deep generative models (DGM) have the potential to transform the lifestyle of consumers and creators. Sony R&D is developing large-scale DGM technologies for content generation and restoration, which we simply call Sony DGM. We expect Sony DGM to become an integral part of the music, film, and gaming industries in the years to come, and knowing that we at Sony R&D have the unique opportunity to work directly with world-leading entertainment groups within these industries, we want to make the most of this possibility. Current Sony DGM contains two categories: diffusion-based models and stochastic vector quantization technique. We will briefly introduce our current work below. Demonstration of image generation and media restoration are available from the https://sony.github.io/creativeai
GibbsDDRM
Accepted at ICML 2023 as oral
TL;DR: Solving blind linear inverse problems by utilizing the pre-trained diffusion
models in a Gibbs sampling manner.
Pre-trained diffusion models have been successfully used as priors in a variety of
linear inverse problems, where the
goal is to reconstruct a signal given a noisy linear measurement. However, existing
approaches require knowledge of the
linear operator. In this paper, we propose GibbsDDRM, an extension of the Denoising
Diffusion Restoration Models (DDRM)
to the blind setting where the linear measurement operator is unknown. It constructs the
joint distribution of data,
measurements, and linear operator using a pre-trained diffusion model as the data prior,
and solves the problem by
posterior sampling using an efficient variant of a Gibbs sampler. The proposed method is
problem-agnostic, meaning that
a pre-trained diffusion model can be applied to various inverse problems without
fine-tuning. Experimentally, it
achieves high performance in both blind image deblurring and vocal dereverberation(*)
tasks, despite using simple
generic priors for the underlying linear operators. This technology is expected to be
utilized in content editing in
music and film production fields.
(*) We have confirmed that Gibbs DDRM improves the performance of DiffDereverb,
which is presented in our ICASSP2023
paper titled "Unsupervised vocal dereverberation with diffusion-based generative
models", thanks to the novel sampling
scheme.

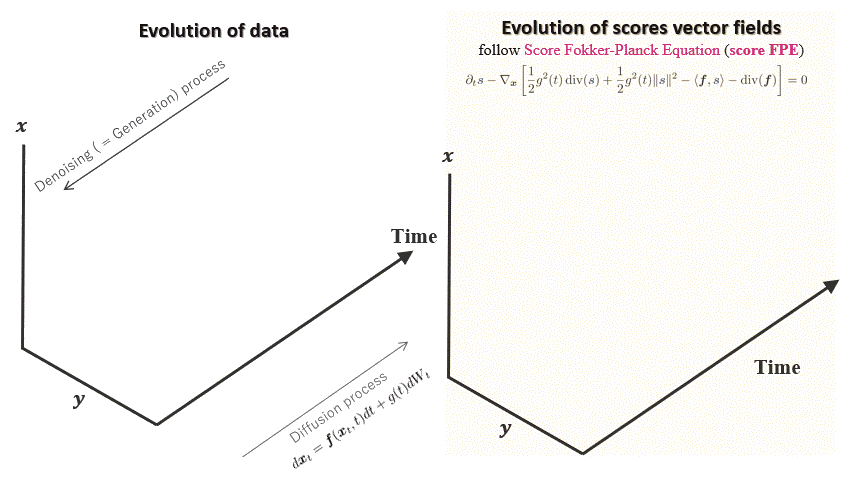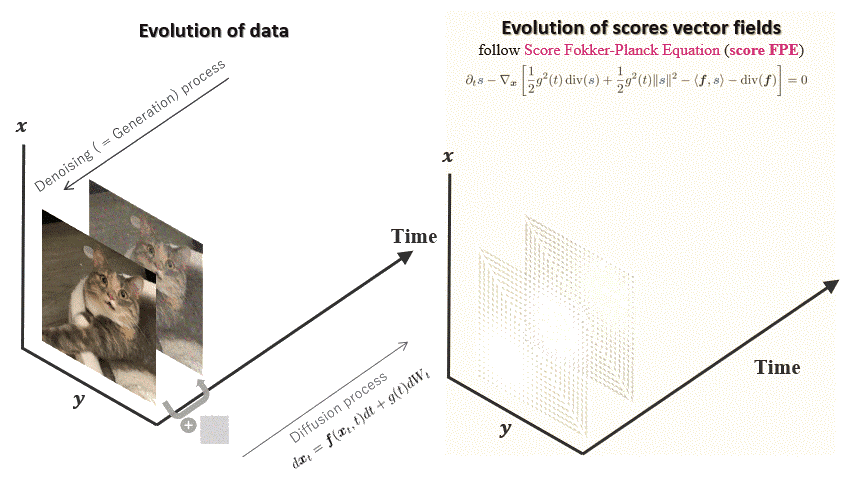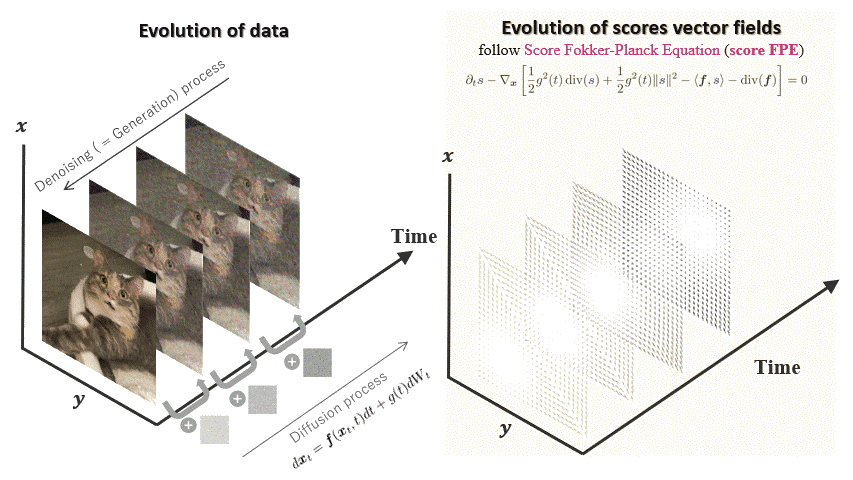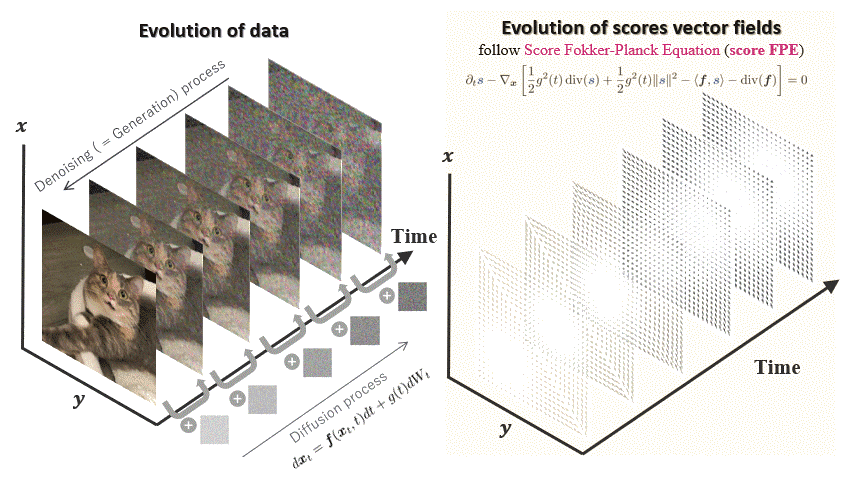
FP-Diffusion
Accepted at ICML 2023
TL;DR: Improving density estimation of diffusion models by regularizing with the
underlying equation describing the
temporal evolution of scores, theoretically supported.
Diffusion models learn a family of noise-conditional score functions corresponding to
the data density perturbed with
increasingly large amounts of noise. These perturbed data densities are tied together by
the Fokker-Planck equation
(FPE), a partial differential equation (PDE) governing the spatial-temporal evolution of
a density undergoing a
diffusion process. In this work, we derive a corresponding equation, called the score
FPE that characterizes the
noise-conditional scores of the perturbed data densities (i.e., their gradients).
Surprisingly, despite impressive
empirical performance, we observe that scores learned via denoising score matching (DSM)
do not satisfy the underlying
score FPE. We prove that satisfying the FPE is desirable as it improves the likelihood
and the degree of conservativity.
Hence, we propose to regularize the DSM objective to enforce satisfaction of the score
FPE, and we show the
effectiveness of this approach across various datasets.
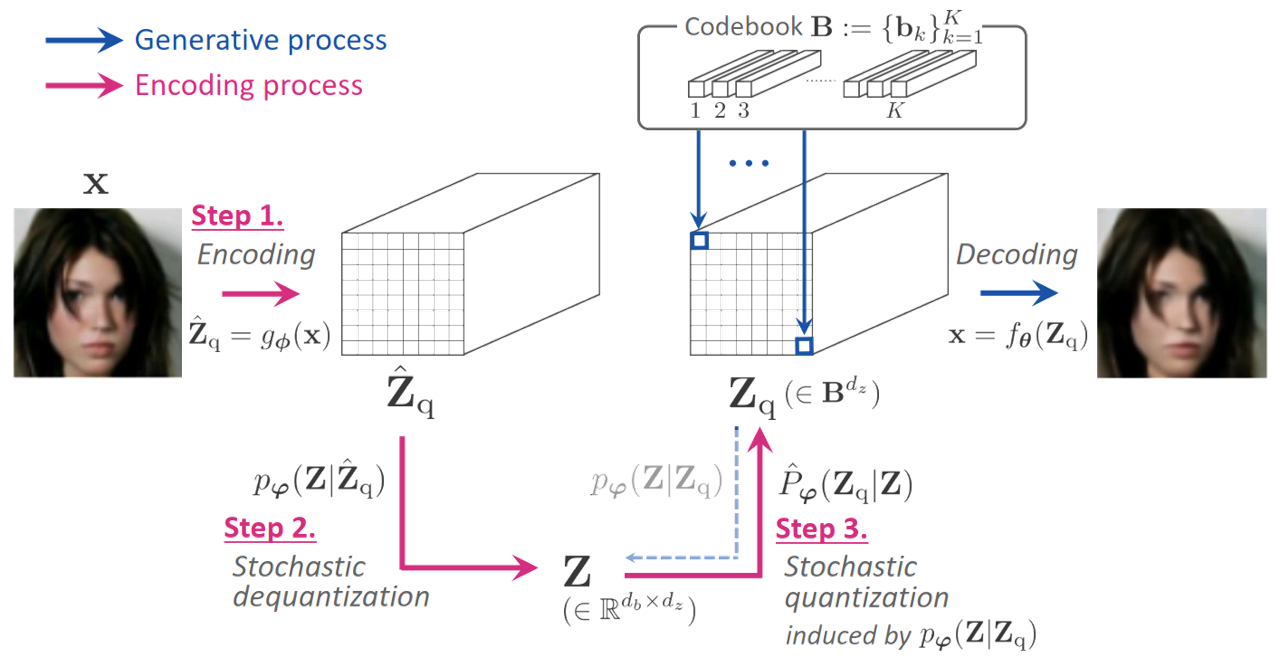
SQ-VAE
Presented at ICML 2022
TL;DR: Training vector quantization efficiently and stably with variational Bayes
framework.
One noted issue of vector-quantized variational autoencoder (VQ-VAE) is that the learned
discrete representation uses
only a fraction of the full capacity of the codebook, also known as codebook collapse.
We hypothesize that the training
scheme of VQ-VAE, which involves some carefully designed heuristics, underlies this
issue. In this paper, we propose a
new training scheme that extends the standard VAE via novel stochastic dequantization
and quantization, called
stochastically quantized variational autoencoder (SQ-VAE). In SQ-VAE, we observe a trend
that the quantization is
stochastic at the initial stage of the training but gradually converges toward a
deterministic quantization, which we
call self-annealing. Our experiments show that SQ-VAE improves codebook utilization
without using common heuristics.
Furthermore, we empirically show that SQ-VAE is superior to VAE and VQ-VAE in vision-
and speech-related tasks.
Technology 05Neural RGB-D Fusion Models for Sparse Time-of-Flight Sensing
At Sony we believe that active depth sensing is key to more robust, reliable, and real-time 3D perception. However, depth sensing for mobile devices comes with many challenges, among all low power constraints. We present a software pipeline providing dense depth maps from a sparse time-of-flight (ToF) sensor and a single RGB camera. Our pipeline relies on an original neural depth completion model running at real-time frame rates on a Qualcomm Smartphone Reference Design board equipped with a sparse ToF sensor. Our solution is designed to minimize power consumption whilst providing depth maps viable for AR/VR use-cases.

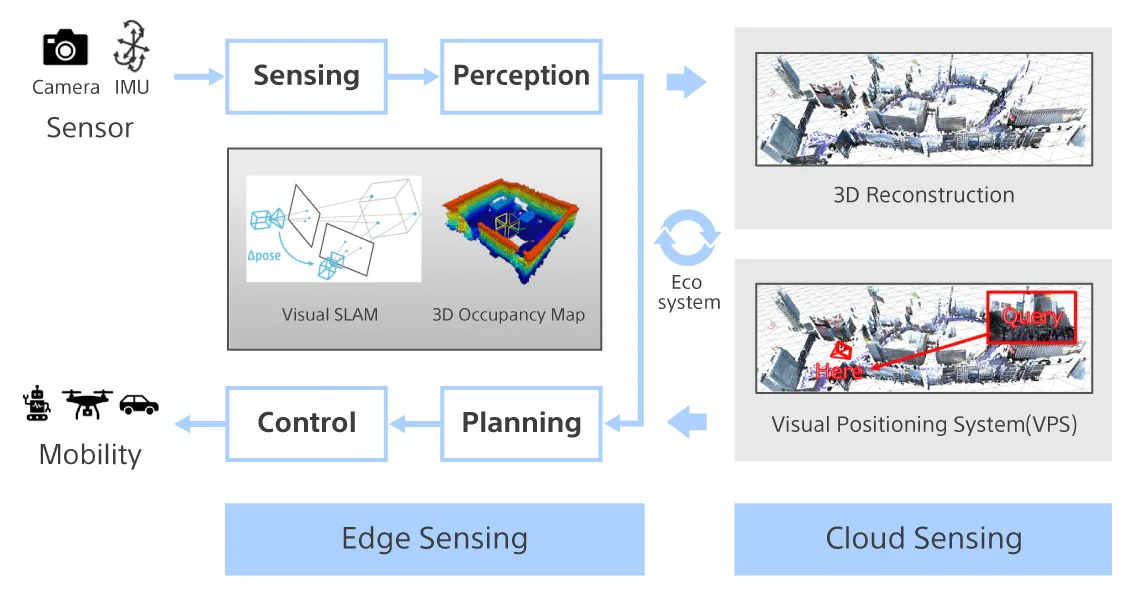
Technology 06Sony's 3D Environment Sensing - Research and Applications -
3D Environment Sensing is a technology which analyzes photos taken by a device to make it aware of its environment and estimate its position, then recreates a realistic 3D model of its surroundings. Applications include a wide range of fields, such as the entertainment, robotics, and video production industries.
Publications
Other Conferences
-

- AUGUST 19 – 25 2023
- Macao, S.A.R
IJCAI 2023
The 32nd International Joint Conference on Artificial Intelligence
View our activities -

- AUGUST 6 – 10 2023
- Los Angeles, US
SIGGRAPH 2023
The 50th International Conference & Exhibition on Computer Graphics & Interactive Techniques (SIGGRAPH)
View our activities