
- DECEMBER 10 – 16, 2023
- NEW ORLEANS, US
NeurIPS 2023
Thirty-seventh Conference on Neural Information Processing Systems (NeurIPS 23)
We look forward to this year's exciting sponsorship and exhibition opportunities, featuring a variety of ways to connect with participants in person. Sony will exhibit and participate as a Platinum sponsor.
Recruiting information for NeurIPS-2023
We look forward to working with highly motivated individuals to fill the world with emotion and to pioneer future innovation through dreams and curiosity. With us, you will be welcomed onto diverse, innovative, and creative teams set out to inspire the world.
At this time, the full-time and internship roles previously listed on this page are closed.
Please see all other open positions through the links below.
Sony AI: https://ai.sony/joinus/jobroles/
Global Careers Page: https://www.sony.com/en/SonyInfo/Careers/japan/
NOTE: For those interested in Japan-based full-time and internship opportunities, please note the following points and benefits:
・Japanese language skills are NOT required, as your work will be conducted in English.
・Regarding Japan-based internships, please note that they are paid, and that we additionally cover round trip flights, visa expenses, commuting expenses, and accommodation expenses as part of our support package.
・Regarding Japan-based full-time roles, in addition to your compensation and benefits package, we cover your flight to Japan, shipment of your belongings to Japan, visa expenses, commuting expenses, and more!
Workshop
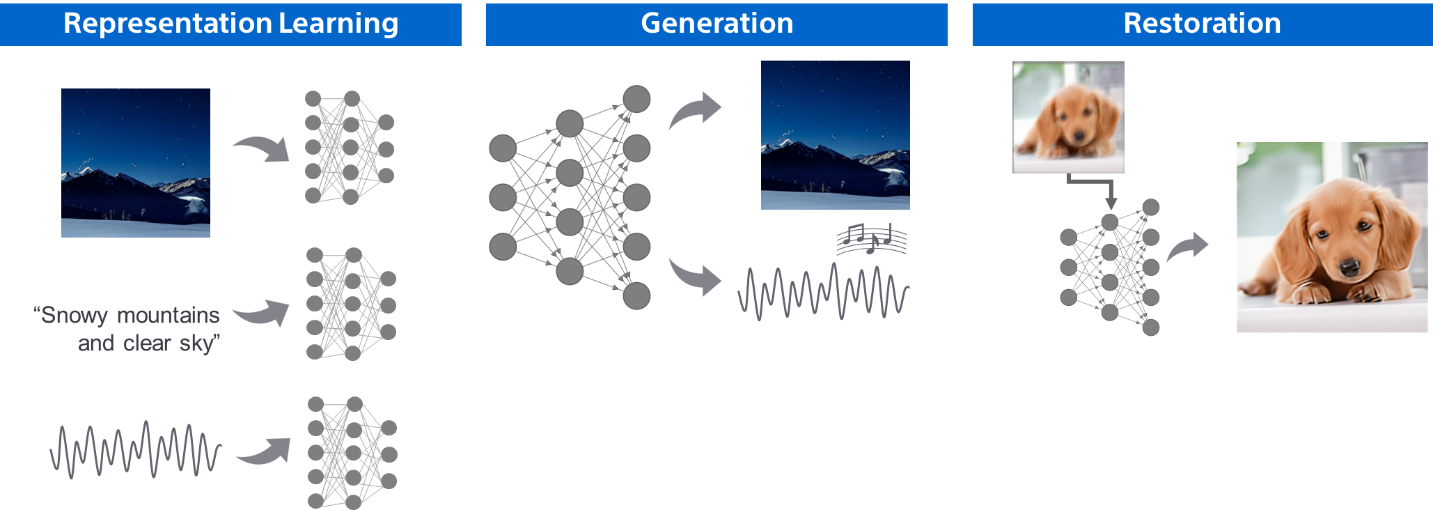
Workshop 01 Sony’s Media Content Restoration and Editing with Deep Generative Models and Beyond.
We showcase Sony's media content restoration and editing technologies based on deep generative models in a two-part workshop. The first section highlights our latest work on deep generative models, covering general purposes. In the second part, interactive demos focus on content restoration and editing using generative modeling and machine learning tools. Our applications meet professional music industry standards and have contributed to commercial products, particularly in AI-powered music production. We welcome participants to engage in demos, discussing practical applications, and exploring the potential of deep generative models.
- Title:
- Sony’s Media Content Restoration and Editing with Deep Generative Models and Beyond.
- Website:
- https://sony.github.io/creativeai/
- Date:
- December 10, 2023 (Sunday)
- Time:
- 16:00 PM – 18:00 PM (CST)
- Location:
- New Orleans Ernest N. Morial Convention Center, Louisiana, USA
- Room:
- 214
Workshop 02 Goal-Conditioned Reinforcement Learning, Workshop at NeurIPS 2023
The workshop aims to foster an inclusive environment where researchers and practitioners from all backgrounds can engage in discussions and build collaborations on the theory, methods, and applications of goal-conditioned reinforcement learning (GCRL).
Broadly, the workshop will focus on the following topics and problems:
•Connections: What are the connections between GCRL and representation learning, few-shot learning, and self-supervised learning? When does (say) effective representation learning emerge from GCRL?
•Future directions: What are limitations of existing methods, benchmarks, and assumptions?
•Algorithms: How might we improve existing methods, and do this in a way that enables applications to broader domains (e.g., molecular discovery, instruction-following robots)?
- Title:
- Goal-Conditioned Reinforcement Learning, Workshop at NeurIPS 2023
- Website:
- https://goal-conditioned-rl.github.io/2023/
- Date:
- December 15, 2023 (Friday)
- Time:
- 09:00 AM – 17:30 PM (CST)
- Location:
- New Orleans Ernest N. Morial Convention Center, Louisiana, USA
- Room:
- 206-207
Technologies & Business use case




Publications
Publication 01 f-Policy Gradients: A General Framework for Goal-Conditioned RL using f-Divergences
- Authors:
- Siddhant Agarwal, Ishan Durugkar (Sony AI), Amy Zhang, Peter Stone (Sony AI)
- Abstract:
- Goal-Conditioned RL problems provide sparse rewards where the agent receives a reward signal only when it has achieved the goal, making exploration a difficult problem. Several works augment this sparse reward with a learned dense reward function, but this can lead to suboptimality in exploration and misalignment of the task. Moreover, recent works have demonstrated that effective shaping rewards for a particular problem can depend on the underlying learning algorithm. Our work ($f$-PG or $f$-Policy Gradients) shows that minimizing f-divergence between the agent's state visitation distribution and the goal can give us an optimal policy. We derive gradients for various f-divergences to optimize this objective. This objective provides dense learning signals for exploration in sparse reward settings. We further show that entropy maximizing policy optimization for commonly used metric-based shaping rewards like L2 and temporal distance can be reduced to special cases of f-divergences, providing a common ground to study such metric-based shaping rewards. We compare $f$-Policy Gradients with standard policy gradients methods on a challenging gridworld as well as the Point Maze environments.
Publication 02 Elden: Exploration via Local Dependencies
- Authors:
- Zizhao Wang, Jiaheng Hu, Roberto Martín-Martín, Peter Stone (Sony AI)
- Abstract:
- Tasks with large state space and sparse reward present a longstanding challenge to reinforcement learning. In these tasks, an agent needs to explore the state space efficiently until it finds reward: the hard exploration problem. To deal with this problem, the community has proposed to augment the reward function with intrinsic reward, a bonus signal that encourages the agent to visit interesting states. In this work, we propose a new way of defining interesting states for environments with factored state spaces and complex chained dependencies, where an agent's actions may change the state of one factor that, in order, may affect the state of another factor. This is natural in human environments such as homes where the agent's actions can change the state of one object/factor (switch on/off a stove), which influences the state of another object/factor (heat a pan above the stove). Our insight is that, in these environments, interesting states for exploration are states where the agent is uncertain whether (as opposed to how) entities such as the agent or objects have some influence on each other. We present ELDEN, Exploration via Local DepENdencies, a novel intrinsic reward that encourages the discovery of new interactions between entities. ELDEN utilizes a novel scheme --- the partial derivative of the learned dynamics to model the local dependencies between entities accurately and computationally efficiently. Then the uncertainty of the predicted dependencies is used as an intrinsic reward to encourage exploration toward new interactions. We evaluate the performance of ELDEN on three different domains with complex dependencies, ranging from 2D grid worlds to 3D robotic tasks. In all domains, ELDEN is able to correctly recover local dependencies and learn successful policies, significantly outperforming previous state-of-the-art exploration methods.
Publication 03 FAMO: Fast Adaptive Multitask Optimization
- Authors:
- Bo Liu, Yihao Feng, Peter Stone (Sony AI), Qiang Liu
- Abstract:
- One of the grand enduring goals of AI is to create generalist agents that can learn multiple different tasks from diverse data via multitask learning (MTL). However, gradient descent (GD) on the average loss across all tasks may yield poor multitask performance due to severe under-optimization of certain tasks. Previous approaches that manipulate task gradients for a more balanced loss decrease require storing and computing all task gradients (O(K) space and time where K is the number of tasks), limiting their use in large-scale scenarios. In this work, we introduce Fast Adaptive Multitask Optimization (FAMO), a dynamic weighting method that decreases task losses in a balanced way using O(1) space and time. We conduct an extensive set of experiments covering multi-task supervised and reinforcement learning problems. Our results indicate that FAMO achieves comparable or superior performance to state-of-the-art gradient manipulation techniques while offering significant improvements in space and computational efficiency. Code is available at https://github.com/Cranial-XIX/FAMO."
Publication 04 LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning
- Authors:
- Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, Peter Stone (Sony AI)
- Abstract:
- Lifelong learning offers a promising paradigm of building a generalist agent that learns and adapts over its lifespan. Unlike traditional lifelong learning problems in image and text domains, which primarily involve the transfer of declarative knowledge of entities and concepts, lifelong learning in decision-making (LLDM) also necessitates the transfer of procedural knowledge, such as actions and behaviors. To advance research in LLDM, we introduce LIBERO, a novel benchmark of lifelong learning for robot manipulation. Specifically, LIBERO highlights five key research topics in LLDM: 1) how to efficiently transfer declarative knowledge, procedural knowledge, or the mixture of both; 2) how to design effective policy architectures and 3) effective algorithms for LLDM; 4) the robustness of a lifelong learner with respect to task ordering; and 5) the effect of model pretraining for LLDM. We develop an extendible procedural generation pipeline that can in principle generate infinitely many tasks. For benchmarking purpose, we create four task suites (130 tasks in total) that we use to investigate the above-mentioned research topics. To support sample-efficient learning, we provide high-quality human-teleoperated demonstration data for all tasks. Our extensive experiments present several insightful or even unexpected discoveries: sequential finetuning outperforms existing lifelong learning methods in forward transfer, no single visual encoder architecture excels at all types of knowledge transfer, and naive supervised pretraining can hinder agents' performance in the subsequent LLDM. Check the website at this https URL (https://libero-project.github.io/) for the code and the datasets.
Publication 05 Privacy Assessment on Reconstructed Images: Are Existing Evaluation Metrics Faithful to Human Perception?
- Authors:
- Xiaoxiao Sun, Nidham Gazagnadou (Sony AI), Vivek Sharma (Sony AI), Lingjuan Lyu (Sony AI), Hongdong Li, Liang Zheng
- Abstract:
- Hand-crafted image quality metrics, such as PSNR and SSIM, are commonly used to evaluate model privacy risk under reconstruction attacks. Under these metrics, reconstructed images that are determined to resemble the original one generally indicate more privacy leakage. Images determined as overall dissimilar, on the other hand, indicate higher robustness against attack. However, there is no guarantee that these metrics well reflect human opinions, which, as a judgement for model privacy leakage, are more trustworthy. In this paper, we comprehensively study the faithfulness of these hand-crafted metrics to human perception of privacy information from the reconstructed images. On 5 datasets ranging from natural images, faces, to fine-grained classes, we use 4 existing attack methods to reconstruct images from many different classification models and, for each reconstructed image, we ask multiple human annotators to assess whether this image is recognizable. Our studies reveal that the hand-crafted metrics only have a weak correlation with the human evaluation of privacy leakage and that even these metrics themselves often contradict each other. These observations suggest risks of current metrics in the community. To address this potential risk, we propose a learning-based measure called SemSim to evaluate the Semantic Similarity between the original and reconstructed images. SemSim is trained with a standard triplet loss, using an original image as an anchor, one of its recognizable reconstructed images as a positive sample, and an unrecognizable one as a negative. By training on human annotations, SemSim exhibits a greater reflection of privacy leakage on the semantic level. We show that SemSim has a significantly higher correlation with human judgment compared with existing metrics. Moreover, this strong correlation generalizes to unseen datasets, models and attack methods. We envision this work as a milestone for image quality evaluation closer to the human level. The project page is https://sites.google.com/view/semsim.
Publication 06 STARSS23: An Audio-Visual Dataset of Spatial Recordings of Real Scenes with Spatiotemporal Annotations of Sound Events
- Authors:
- Kazuki Shimada (Sony AI), Archontis Politis, Parthasaarathy Sudarsanam, Daniel Krause, Kengo Uchida (Sony AI), Sharath Adavanne, Aapo Hakala, Yuichiro Koyama, Naoya Takahashi (Sony AI), Shusuke Takahashi, Tuomas Virtanen, Yuki Mitsufuji (Sony AI)
- Abstract:
- While direction of arrival (DOA) of sound events is generally estimated from multichannel audio data recorded in a microphone array, sound events usually derive from visually perceptible source objects, e.g., sounds of footsteps come from the feet of a walker. This paper proposes an audio-visual sound event localization and detection (SELD) task, which uses multichannel audio and video information to estimate the temporal activation and DOA of target sound events. Audio visual SELD systems can detect and localize sound events using signals from a microphone array and audio-visual correspondence. We also introduce an audio visual dataset, Sony-TAu Realistic Spatial Soundscapes 2023 (STARSS23), which consists of multichannel audio data recorded with a microphone array, video data, and spatiotemporal annotation of sound events. Sound scenes in STARSS23 are recorded with instructions, which guide recording participants to ensure adequate activity and occurrences of sound events. STARSS23 also serves human-annotated temporal activation labels and human-confirmed DOA labels, which are based on tracking results of a motion capture system. Our benchmark results show that the audio-visual SELD system achieves lower localization error than the audio-only system. The data is available at https://zenodo.org/record/7880637.
Publication 07 Ethical Considerations for Responsible Data Curation
- Authors:
- Jerone Andrews (Sony AI), Dora Zhao (Sony AI), William Thong (Sony AI), Apostolos Modas (Sony AI), Orestis Papakyriakopoulos (Sony AI), Alice Xiang (Sony AI)
- Abstract:
- Human-centric computer vision (HCCV) data curation practices often neglect privacy and bias concerns, leading to dataset retractions and unfair models. HCCV datasets constructed through nonconsensual web scraping lack crucial metadata for comprehensive fairness and robustness evaluations. Current remedies are post hoc, lack persuasive justification for adoption, or fail to provide proper contextualization for appropriate application. Our research focuses on proactive, domain-specific recommendations, covering purpose, privacy and consent, as well as diversity, for curating HCCV evaluation datasets, addressing privacy and bias. We adopt an ante hoc reflective perspective, drawing from current practices, guidelines, dataset withdrawals, and audits, to inform our considerations and recommendations.
Publication 08 Posthoc privacy guarantees for collaborative inference with modified Propose-Test-Release
- Authors:
- JAbhishek Singh, Praneeth Vepakomma, Vivek Sharma (Sony AI), Ramesh Raskar
- Abstract:
- Cloud-based machine learning inference is an emerging paradigm where users query by sending their data through a service provider who runs an ML model on that data and returns back the answer. Due to increased concerns over data privacy, recent works have proposed Collaborative Inference (CI) to learn a privacy-preserving encoding of sensitive user data before it is shared with an untrusted service provider. Existing works so far evaluate the privacy of these encodings through empirical reconstruction attacks. In this work, we develop a new framework that provides formal privacy guarantees for an arbitrarily trained neural network by linking its local Lipschitz constant with its local sensitivity. To guarantee privacy using local sensitivity, we extend the Propose-Test-Release (PTR) framework to make it tractable for neural network queries. We verify the efficacy of our framework experimentally on real-world datasets and elucidate the role of Adversarial Representation Learning (ARL) in improving the privacy-utility trade-off. The project page is https://tremblerz.github.io/posthoc
Publication 09 Aging with GRACE: Lifelong Model Editing with Discrete Key-Value Adaptors
- Authors:
- Thomas Hartvigsen, Swami Sankaranarayanan (Sony AI), Hamid Palangi, Yoon Kim, Marzyeh Ghassemi
- Abstract:
- Deployed models decay over time due to shifting inputs, changing user needs, or emergent knowledge gaps. When harmful behaviors are identified, targeted edits are required. However, current model editors, which adjust specific behaviors of pre-trained models, degrade model performance over multiple edits. We propose GRACE, a Lifelong Model Editing method, which implements spot-fixes on streaming errors of a deployed model, ensuring minimal impact on unrelated inputs. GRACE writes new mappings into a pre-trained model's latent space, creating a discrete, local codebook of edits without altering model weights. This is the first method enabling thousands of sequential edits using only streaming errors. Our experiments on T5, BERT, and GPT models show GRACE's state-of-the-art performance in making and retaining edits, while generalizing to unseen inputs.
Publication 10 Towards a fuller understanding of neurons with Clustered Compositional Explanations
- Authors:
- Biagio La Rosa, Leilani H. Gilpin, Roberto Capobianco (Sony AI)
- Abstract:
- Compositional Explanations is a method for identifying logical formulas of concepts that approximate the neurons' behavior. However, these explanations are linked to the small spectrum of neuron activations used to check the alignment (i.e., the highest ones), thus lacking completeness. In this paper, we propose a generalization, called Clustered Compositional Explanations, that combines Compositional Explanations with clustering and a novel search heuristic to approximate a broader spectrum of the neuron behavior. We define, and address the problems connected to the application of these methods to multiple ranges of activations, analyze the insights retrievable by using our algorithm, and propose some desiderata qualities that can be used to study the explanations returned by different algorithms.
Publication 11 Where Did I Come From? Origin Attribution of AI-Generated Images
- Authors:
- Zhenting Wang (Sony AI intern), Chen Chen (Sony AI), Yi Zeng (Sony AI intern), Lingjuan Lyu (SonyAI), Shiqing Ma
- Abstract:
- Image generation techniques have been gaining increasing attention recently, but concerns have been raised about the potential misuse and intellectual property (IP) infringement associated with image generation models. It is, therefore, necessary to analyze the origin of images by inferring if a specific image was generated by a particular model, i.e., origin attribution. Existing methods only focus on specific types of generative models and require additional procedures during the training phase or generation phase. This makes them unsuitable for pre-trained models that lack these specific operations and may impair generation quality. To address this problem, we first develop an alteration-free and model-agnostic origin attribution method via reverse-engineering on image generation models, i.e., inverting the input of a particular model for a specific image. Given a particular model, we first analyze the differences in the hardness of reverse-engineering tasks for generated samples of the given model and other images. Based on our analysis, we then propose a method that utilizes the reconstruction loss of reverse-engineering to infer the origin. Our proposed method effectively distinguishes between generated images of a specific generative model and other images, i.e., images generated by other models and real images.
Publication 12 Is Heterogeneity Notorious? Taming Heterogeneity to Handle Test-Time Shift in Federated Learning
- Authors:
- Yue Tan (Sony AI intern), Chen Chen (Sony AI), Weiming Zhuang (Sony AI), Xin Dong (Sony AI), Lingjuan Lyu (Sony AI), Guodong Long
- Abstract:
- Federated learning (FL) is an effective machine learning paradigm where multiple clients can train models based on heterogeneous data in a decentralized manner without accessing their private data. However, existing FL systems undergo performance deterioration due to feature-level test-time shifts, which are well investigated in centralized settings but rarely studied in FL. The common non-IID issue in FL usually refers to inter-client heterogeneity during training phase, while the test-time shift refers to the intra-client heterogeneity during test phase. Although the former is always deemed to be notorious for FL, there is still a wealth of useful information delivered by heterogeneous data sources, which may potentially help alleviate the latter issue. To explore the possibility of using inter-client heterogeneity in handling intra-client heterogeneity, we firstly propose a contrastive learning-based FL framework, namely FedICON, to capture invariant knowledge among heterogeneous clients and consistently tune the model to adapt to test data. In FedICON, each client performs sample-wise supervised contrastive learning during the local training phase, which enhances sample-wise invariance encoding ability. Through global aggregation, the invariance extraction ability can be mutually boosted among inter-client heterogeneity. During the test phase, our test-time adaptation procedure leverages unsupervised contrastive learning to guide the model to smoothly generalize to test data under intra-client heterogeneity. Extensive experiments validate the effectiveness of the proposed FedICON in taming heterogeneity to handle test-time shift problems.
Publication 13 Towards Personalized Federated Learning via Heterogeneous Model Reassembly
- Authors:
- Jiaqi Wang, Xingyi Yang, Suhan Cui, Liwei Che, Lingjuan Lyu (Sony AI), Dongkuan Xu, Fenglong Ma
- Abstract:
- This paper focuses on addressing the practical yet challenging problem of model heterogeneity in federated learning, where clients possess models with different network structures. To track this problem, we propose a novel framework called pFedHR, which leverages heterogeneous model reassembly to achieve personalized federated learning. In particular, we approach the problem of heterogeneous model personalization as a model-matching optimization task on the server side. Moreover, pFedHR automatically and dynamically generates informative and diverse personalized candidates with minimal human intervention. Furthermore, our proposed heterogeneous model reassembly technique mitigates the adverse impact introduced by using public data with different distributions from the client data to a certain extent. Experimental results demonstrate that pFedHR outperforms baselines on three datasets under both IID and Non-IID settings. Additionally, pFedHR effectively reduces the adverse impact of using different public data and dynamically generates diverse personalized models in an automated manner.
Publication 14 UltraRE: Enhancing RecEraser for Recommendation Unlearning via Error Decomposition
- Authors:
- Yuyuan Li, Chaochao Chen, Yizhao Zhang, Weiming Liu, Lingjuan Lyu (Sony AI), Xiaolin Zheng, Dan Meng, Jun Wang
- Abstract:
- With growing concerns regarding privacy in machine learning models, regulations have committed to granting individuals the right to be forgotten while mandating companies to develop non-discriminatory machine learning systems, thereby fueling the study of the machine unlearning problem. Our attention is directed toward a practical unlearning scenario, i.e., recommendation unlearning. As the state-of-the-art framework, i.e., RecEraser, naturally achieves full unlearning completeness, our objective is to enhance it in terms of model utility and unlearning efficiency. In this paper, we rethink RecEraser from an ensemble-based perspective and focus on its three potential losses, i.e., redundancy, relevance, and combination. Under the theoretical guidance of the above three losses, we propose a new framework named UltraRE, which simplifies and powers RecEraser for recommendation tasks. Specifically, for redundancy loss, we incorporate transport weights in the clustering algorithm to optimize the equilibrium between collaboration and balance while enhancing efficiency; for relevance loss, we ensure that sub-models reach convergence on their respective group data; for combination loss, we simplify the combination estimator without compromising its efficacy. Extensive experiments on three real-world datasets demonstrate the effectiveness of UltraRE.
Publication 15 Differentially Private Image Classification by Learning Priors from Random Processes
- Authors:
- Xinyu Tang, Ashwinee Panda, Vikash Sehwag (Sony AI), Prateek Mittal
- Abstract:
- In privacy-preserving machine learning, differentially private stochastic gradient descent (DP-SGD) performs worse than SGD due to per-sample gradient clipping and noise addition. A recent focus in private learning research is improving the performance of DP-SGD on private data by incorporating priors that are learned on real-world public data. In this work, we explore how we can improve the privacy-utility tradeoff of DP-SGD by learning priors from images generated by random processes and transferring these priors to private data. We propose DP-RandP, a three-phase approach. We attain new state-of-the-art accuracy when training from scratch on CIFAR10, CIFAR100, and MedMNIST for a range of privacy budgets ε∈[1,8]. In particular, we improve the previous best reported accuracy on CIFAR10 from 60.6% to 72.3% for ε=1. Our code is available at https://github.com/inspire-group/DP-RandP.
Publication 16 FRUNI and FTREE synthetic knowledge graphs for evaluating explainability
- Authors:
- Pablo Sanchez Martin (Sony AI), Tarek Besold (Sony AI), Priyadarshini Kumari (Sony AI)
- Abstract:
- Research on knowledge graph completion (KGC)---i.e., link prediction within incomplete KGs---is witnessing significant growth in popularity. Recently, KGC using KG embedding (KGE) models, primarily based on complex architectures (e.g., transformers), have achieved remarkable performance. Still, extracting the \emph{minimal and relevant} information employed by KGE models to make predictions, while constituting a major part of \emph{explaining the predictions}, remains a challenge. While there exists a growing literature on explainers for trained KGE models, systematically exposing and quantifying their failure cases poses even greater challenges. In this work, we introduce two synthetic datasets, FRUNI and FTREE, designed to demonstrate the (in)ability of explainer methods to spot link predictions that rely on indirectly connected links. Notably, we empower practitioners to control various aspects of the datasets, such as noise levels and dataset size, enabling them to assess the performance of explainability methods across diverse scenarios. Through our experiments, we assess the performance of four recent explainers in providing accurate explanations for predictions on the proposed datasets. We believe that these datasets are valuable resources for further validating explainability methods within the knowledge graph community.
Publication 17 The 3rd ; NeurIPS Workshop on Efficient Natural Language and Speech Processing (ENLSP) Efficient Infusion of Self-supervised Representations in Automatic Speech Recognition
- Authors:
- Darshan Prabhu (Sony Research India), Sai Ganesh Misishkar (Sony Research India), Pankaj Wasnik (Sony Research India)
- Abstract:
- Self-supervised learned (SSL) models such as Wav2vec and HuBERT yield state-of-the-art results on speech-related tasks. Given the effectiveness of such models, it is advantageous to use them in conventional ASR systems. While some approaches suggest incorporating these models as a trainable encoder or a learnable frontend, training such systems is extremely slow and requires a lot of computation cycles. In this work, we propose two simple approaches that use (1) framewise addition and (2) cross-attention mechanisms to efficiently incorporate the representations from the SSL model(s) into the ASR architecture, resulting in models that are comparable in size with standard encoder-decoder conformer systems while also avoiding the usage of SSL models during training. Our approach results in faster training and yields significant performance gains on the Librispeech and Tedlium datasets compared to baselines. We further provide detailed analysis and ablation studies that demonstrate the effectiveness of our approach.