
- JULY 23 – 29 2023
- Hawaii, US
- ML
ICML 2023
Fortieth International Conference on Machine Learning (ICML)
The International Conference on Machine Learning (ICML) is the premier gathering of professionals dedicated to the advancement of the branch of artificial intelligence known as machine learning. ICML is globally renowned for presenting and publishing cutting-edge research on all aspects of machine learning used in closely related areas like artificial intelligence, statistics and data science, as well as important application areas such as machine vision, computational biology, speech recognition, and robotics.
We look forward to this year's exciting sponsorship and exhibition opportunities, featuring a variety of ways to connect with participants in person. Sony will exhibit and participate as a Silver sponsor.
Recruiting information for ICML-2023
We look forward to working with highly motivated individuals to fill the world with emotion and to pioneer future innovation through dreams and curiosity. With us, you will be welcomed onto diverse, innovative, and creative teams set out to inspire the world.
At this time, the full-time and internship roles previously listed on this page are closed.
As such, please see all our other open positions through the links below.
Sony AI Page:
https://ai.sony/joinus/jobroles/
Global Careers Page:
Sony Group Portal - Global Careers - Careers in Japan
NOTE: For those interested in Japan-based full-time and internship opportunities, please note the following points and benefits:
・Japanese language skills are NOT required, as your work will be conducted in English.
・Regarding Japan-based internships, please note that they are paid, and that we additionally cover round trip flights, visa expenses, commuting expenses, and accommodation expenses as part of our support package.
・Regarding Japan-based full-time roles, in addition to your compensation and benefits package, we cover your flight to Japan, shipment of your belongings to Japan, visa expenses, commuting expenses, and more!
Technologies & Business use case
Technology 01 Deep Generative Modeling
Technologies like deep generative models (DGM) have the potential to transform the lifestyle of consumers and creators. Sony R&D is developing large-scale DGM technologies for content generation and restoration, which we simply call Sony DGM. We expect Sony DGM to become an integral part of the music, film, and gaming industries in the years to come, and knowing that we at Sony R&D have the unique opportunity to work directly with world-leading entertainment groups within these industries, we want to make the most of this possibility. Current Sony DGM contains two categories: diffusion-based models and stochastic vector quantization technique. We will briefly introduce our current work below. Demonstration of image generation and media restoration are available from the https://sony.github.io/creativeai.
GibbsDDRM
Accepted at ICML 2023 as oral
TL;DR: Solving blind linear inverse problems by utilizing the pre-trained diffusion models in a Gibbs sampling
manner.
Pre-trained diffusion models have been successfully used as priors in a variety of linear inverse problems,
where the
goal is to reconstruct a signal given a noisy linear measurement. However, existing approaches require knowledge
of the
linear operator. In this paper, we propose GibbsDDRM, an extension of the Denoising Diffusion Restoration Models
(DDRM)
to the blind setting where the linear measurement operator is unknown. It constructs the joint distribution of
data,
measurements, and linear operator using a pre-trained diffusion model as the data prior, and solves the problem
by
posterior sampling using an efficient variant of a Gibbs sampler. The proposed method is problem-agnostic,
meaning that
a pre-trained diffusion model can be applied to various inverse problems without fine-tuning. Experimentally, it
achieves high performance in both blind image deblurring and vocal dereverberation(*) tasks, despite using
simple
generic priors for the underlying linear operators. This technology is expected to be utilized in content
editing in
music and film production fields.
(*) We have confirmed that Gibbs DDRM improves the performance of DiffDereverb, which is presented in our
ICASSP2023
paper titled "Unsupervised vocal dereverberation with diffusion-based generative models", thanks to the novel
sampling
scheme.

FP-Diffusion
Accepted at ICML 2023
TL;DR: Improving density estimation of diffusion models by regularizing with the underlying equation describing
the
temporal evolution of scores, theoretically supported.
Diffusion models learn a family of noise-conditional score functions corresponding to the data density perturbed
with
increasingly large amounts of noise. These perturbed data densities are tied together by the Fokker-Planck
equation
(FPE), a partial differential equation (PDE) governing the spatial-temporal evolution of a density undergoing a
diffusion process. In this work, we derive a corresponding equation, called the score FPE that characterizes the
noise-conditional scores of the perturbed data densities (i.e., their gradients). Surprisingly, despite
impressive
empirical performance, we observe that scores learned via denoising score matching (DSM) do not satisfy the
underlying
score FPE. We prove that satisfying the FPE is desirable as it improves the likelihood and the degree of
conservativity.
Hence, we propose to regularize the DSM objective to enforce satisfaction of the score FPE, and we show the
effectiveness of this approach across various datasets.
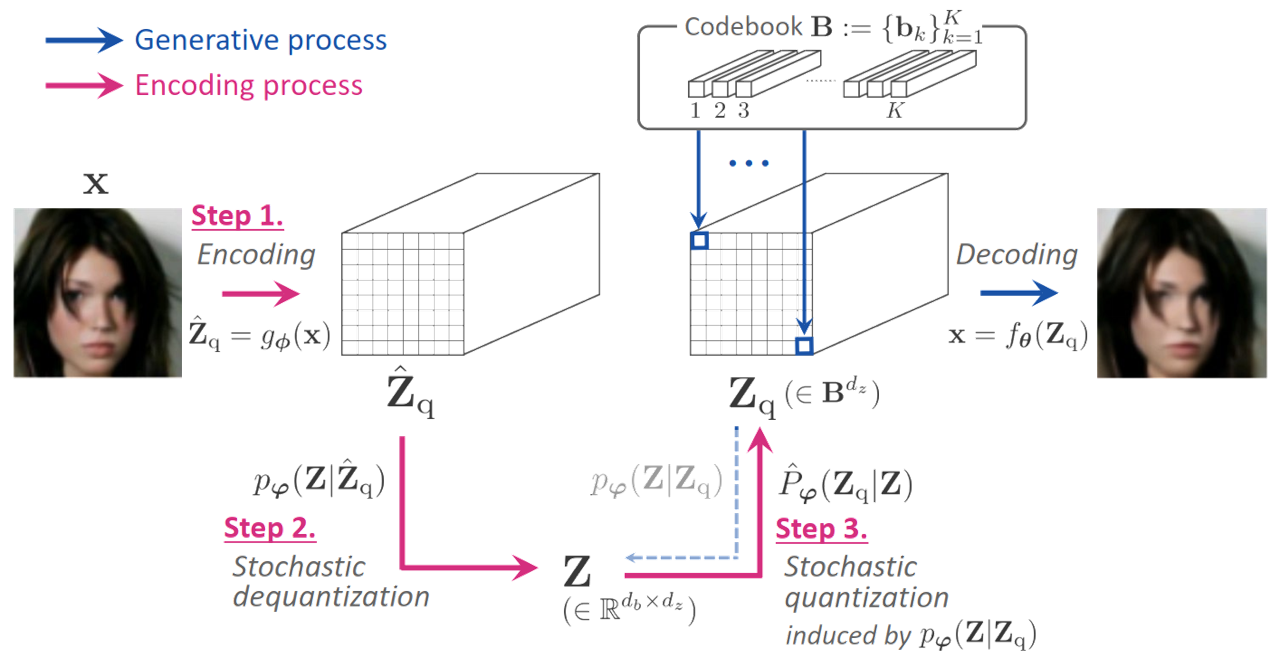
SQ-VAE
Presented at ICML 2022
TL;DR: Training vector quantization efficiently and stably with variational Bayes framework.
One noted issue of vector-quantized variational autoencoder (VQ-VAE) is that the learned discrete representation
uses
only a fraction of the full capacity of the codebook, also known as codebook collapse. We hypothesize that the
training
scheme of VQ-VAE, which involves some carefully designed heuristics, underlies this issue. In this paper, we
propose a
new training scheme that extends the standard VAE via novel stochastic dequantization and quantization, called
stochastically quantized variational autoencoder (SQ-VAE). In SQ-VAE, we observe a trend that the quantization
is
stochastic at the initial stage of the training but gradually converges toward a deterministic quantization,
which we
call self-annealing. Our experiments show that SQ-VAE improves codebook utilization without using common
heuristics.
Furthermore, we empirically show that SQ-VAE is superior to VAE and VQ-VAE in vision- and speech-related tasks.
Technology 02 Unraveling Privacy and Bias in Human-Centric Computer Vision
As human-centric computer vision systems become more widely deployed, there is increasing concern that these systems not only reproduce but also amplify harmful social biases. This talk aims to shed light on the challenges and considerations related to privacy and bias in human-centric computer vision, presenting some of Sony’s approaches to addressing these issues. This talk will cover bias detection tools, human-centric representation learning, as well as domain-specific best practices for operationalizing responsible data curation.
Technology 03 Enhancing games with cutting-edge AI to unlock new possibilities for game developers and players.
We are evolving Game-AI beyond rule-based systems by using deep reinforcement learning to train robust and challenging AI agents in gaming ecosystems. This technology enables game developers to design and deliver richer experiences for players. The recent demonstration of Gran Turismo SophyTM, a trained AI that beat world champions in the PlayStationTM game Gran TurismoTM SPORT, embodies the excitement and possibilities that emerge when modern AI is deployed in a rich gaming environment. As AI technology continues to evolve and mature, we believe it will help spark the imagination and creativity of game designers and players alike.

Can an AI outrace the best human Gran Turismo drivers in the world? Meet Gran Turismo Sophy and find out how the teams at Sony AI, Polyphony Digital Inc., and Sony Interactive Entertainment worked together to create this breakthrough technology. Gran Turismo Sophy is a groundbreaking achievement for AI, but there’s more: it demonstrates the power of AI to deliver new gaming and entertainment experiences.
Publications
Publication 01 Byzantine-Robust Learning on Heterogeneous Data via Gradient Splitting
- Authors
- Yuchen Liu (Sony AI), Chen Chen (Sony AI), Lingjuan Lyu (Sony AI), Fangzhao Wu, Sai Wu, Gang Chen
- Abstract
- Federated learning has exhibited vulnerabilities to Byzantine attacks, where the Byzantine attackers can send arbitrary gradients to the central server to destroy the convergence and performance of the global model. A wealth of defenses have been proposed to defend against Byzantine attacks. However, Byzantine clients can still circumvent defense when the data is non-identically and independently distributed (non-IID). In this paper, we first reveal the root causes of current robust AGgregation Rule (AGR) performance degradation in non-IID settings: the curse of dimensionality and gradient heterogeneity. In order to address this issue, we propose GAS, a gradient splitting based approach that can successfully adapt existing robust AGRs to ensure Byzantine robustness under non-IID settings. We also provide a detailed convergence analysis when the existing robust AGRs are adapted to GAS. Experiments on various real-world datasets verify the efficacy of our proposed GAS.
Publication 02 Revisiting Data-Free Knowledge Distillation with Poisoned Teachers
- Authors
- Junyuan Hong (Sony AI intern), Yi Zeng (Sony AI intern), Shuyang Yu, Lingjuan Lyu (Sony AI), Ruoxi Jia, Jiayu Zhou
- Abstract
- Data-free knowledge distillation (KD) helps realistically transfer knowledge from a pre-trained model (known as the teacher model) to a smaller model (known as the student model) without access to the original training data used for training the teacher model. However, the security of the synthetic or out-of-distribution (OOD) data required in data-free KD is largely unknown and under-explored. In this work, we make the first effort to uncover the security risk of data-free KD w.r.t. untrusted pre-trained models. We then propose ABD, the first plug-in defensive method for data-free KD methods to mitigate the chance of potential backdoors being transferred. We empirically evaluate the effectiveness of our proposed ABD in diminishing transferred backdoor knowledge while maintaining compatible downstream performances as the vanilla KD. We envision this work as a milestone for alarming and mitigating the potential backdoors in data-free KD.
Publication 03 Improving Score-based Diffusion Models by Enforcing the Underlying Score Fokker-Planck Equation
- Authors
- Chieh-Hsin Lai (Sony AI), Yuhta Takida (Sony AI), Naoki Murata (Sony AI), Toshimitsu Uesaka (Sony AI), Yuki Mitsufuji (Sony AI), Stefano Ermon
- Abstract
- Score-based generative models learn a family of noise-conditional score functions corresponding to the data density perturbed with increasingly large amounts of noise. These perturbed data densities are tied together by the Fokker-Planck equation (FPE), a partial differential equation (PDE) governing the spatial-temporal evolution of a density undergoing a diffusion process. In this work, we derive a corresponding equation, called the score FPE that characterizes the noise-conditional scores of the perturbed data densities (i.e., their gradients). Surprisingly, despite impressive empirical performance, we observe that scores learned via denoising score matching (DSM) do not satisfy the underlying score FPE. We prove that satisfying the FPE is desirable as it improves the likelihood and the degree of conservativity. Hence, we propose to regularize the DSM objective to enforce satisfaction of the score FPE, and we show the effectiveness of this approach across various datasets.
Publication 04 GibbsDDRM: A Partially Collapsed Gibbs Sampler for Solving Blind Inverse Problems with Denoising Diffusion Restoration
- Authors
- Naoki Murata (Sony AI), Koichi Saito (Sony AI), Chieh-Hsin Lai (Sony AI), Yuhta Takida (Sony AI), Toshimitsu Uesaka (Sony AI), Yuki Mitsufuji (Sony AI), Stefano Ermon
- Abstract
- Pre-trained diffusion models have been successfully used as priors in a variety of linear inverse problems, where the goal is to reconstruct a signal from noisy linear measurements. However, existing approaches require knowledge of the linear operator. In this paper, we propose GibbsDDRM, an extension of Denoising Diffusion Restoration Models (DDRM) to a blind setting in which the linear measurement operator is unknown. GibbsDDRM constructs a joint distribution of the data, measurements, and linear operator by using a pre-trained diffusion model for the data prior, and it solves the problem by posterior sampling with an efficient variant of a Gibbs sampler. The proposed method is problem-agnostic, meaning that a pre-trained diffusion model can be applied to various inverse problems without fine tuning. In experiments, it achieved high performance on both blind image deblurring and vocal dereverberation tasks, despite the use of simple generic priors for the underlying linear operators.
Publication 05 Men Also Do Laundry: Multi-Attribute Bias Amplification
- Authors
- Dora Zhao (Sony AI), Jerone T. A. Andrews (Sony AI), Alice Xiang (Sony AI)
- Abstract
- As computer vision systems become more widely deployed, there is increasing concern from both the research community and the public that these systems are not only reproducing but amplifying harmful social biases. The phenomenon of bias amplification, which is the focus of this work, refers to models amplifying inherent training set biases at test time. Existing metrics measure bias amplification with respect to single annotated attributes (e.g., computer). However, several visual datasets consist of images with multiple attribute annotations. We show models can learn to exploit correlations with respect to multiple attributes (e.g., {computer, keyboard}), which are not accounted for by current metrics. In addition, we show current metrics can give the erroneous impression that minimal or no bias amplification has occurred as they involve aggregating over positive and negative values. Further, these metrics lack a clear desired value, making them difficult to interpret. To address these shortcomings, we propose a new metric: Multi-Attribute Bias Amplification. We validate our proposed metric through an analysis of gender bias amplification on the COCO and imSitu datasets. Finally, we benchmark bias mitigation methods using our proposed metric, suggesting possible avenues for future bias mitigation.
Publication 06 Principlism Guided Responsible Data Curation
- Authors
- Jerone T. A. Andrews (Sony AI), Dora Zhao (Sony AI), William Thong (Sony AI), Apostolos Modas (Sony AI), Orestis Papakyriakopoulos (Sony AI), Alice Xiang (Sony AI)
- Abstract
- Human-centric computer vision (HCCV) data curation practices often neglect privacy and bias concerns, leading to dataset retractions and unfair models. Further, HCCV datasets constructed through nonconsensual web scraping lack the necessary metadata for comprehensive fairness and robustness evaluations. Current remedies address issues post hoc, lack persuasive justification for adoption, or fail to provide proper contextualization for appropriate application. Our research focuses on proactive, domain-specific recommendations for curating HCCV datasets, addressing privacy and bias. We adopt an ante hoc reflective perspective and draw from current practices and guidelines, guided by the ethical framework of principlism.
Other Conferences
-

- June 4 ~ 10, 2023
- Rhodes island, Greece
- Signal Processing
ICASSP 2023
2023 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2023)
View our activities -

- May 29 ~ June 2, 2023
- London, UK
- Robotics
ICRA 2023
2023 IEEE International Conference on Robotics and Automation (ICRA)
View our activities